MacOS 终端高效压缩大目录指南:告别慢速度,充分利用多核CPU 在使用 macOS 时,我们常会遇到需要打包压缩大目录的场景——比如备份项目文件、传输大型数据集等。默认的终端压缩工具多为单线程,处理大目录时不仅速度慢,还会浪费多核 CPU 的性能。今天就分享一套高效解决方案,让你在终端里快速压缩大目录,兼顾速度与压缩体积。 一、核心方案:tar + pigz 并行压缩(首选)macOS 自带的 gzip 是单线程压缩工具,处理几 GB 甚至几十 GB 的大目录 2026-01-13 MacOS #MacOS #终端
Docker安装EMQX5.8并支持ssl证书连接和启用双向认证 要让Docker部署的EMQ X 5.8支持SSL证书连接并启用双向认证,需完成证书准备、配置EMQ X、Docker启动三个核心步骤。以下是详细操作指南: 一、准备SSL证书(双向认证需要服务端+客户端证书)双向认证需要CA证书、服务端证书/私钥、客户端证书/私钥。可通过OpenSSL自签(测试用)或购买权威CA证书(生产用)。 1. 自签证书示例(OpenSSL)# 创建证书目录 mkdir 2025-11-30 运维 #Docker #EMQX #MQTT #MQ
跨云网络打通实战:阿里云与腾讯云通过 StrongSwan 实现 VPC 互通并中转访问运维网络 在多云架构日益普及的今天,企业常常需要在不同云厂商之间打通私有网络,实现资源互通、数据同步或统一运维。本文将详细介绍如何通过 StrongSwan IPsec 站点到站点(Site-to-Site)VPN,实现 阿里云 VPC_A(172.20.0.0/16) 与 腾讯云 VPC_B(172.16.0.0/16) 的双向互通,并进一步利用 VPC_A 作为中转节点,使腾讯云 VPC_B 能够访问 2025-10-26 运维 #VPN #IPsec #组网 #跨云互通
手把手教你用 iperf3 进行专业网络测速 手把手教你用 iperf3 进行专业网络测速在日常工作和生活中,我们经常会遇到网络卡顿、传输速度慢等问题,此时准确了解网络的实际性能就显得尤为重要。而 iperf3 作为一款强大的网络性能测试工具,能够帮助我们精准测量网络带宽、延迟、丢包率等关键指标。今天,这篇博客就将从工具介绍、安装步骤、测速方法到常见问题解决,全方位带大家掌握用 iperf3 进行网络测速的技能。 一、iperf3 是什么?为 2025-10-21 运维 #iperf3 #网络
csv超大文件拆分sh脚本 这个版本通过参数化设计增强了脚本的灵活性,同时保持了原有高效处理大文件的特性,能够适应各种实际数据处理场景的需求。 以下是支持参数输入的增强版脚本,支持灵活指定输入输出路径和行数限制:#!/bin/bash # 使用方法函数 usage() { echo "用法: $0 [-i 输入文件] [-o 输出前缀] [-e Excel最大行数]" echo "示例: $0 2025-05-05 数据 #Linux #Shell #CSV
CentOS7 编译安装Python3.10 1.安装openssl 1.1.1kcurl -O https://ftp.openssl.org/source/openssl-1.1.1k.tar.gz \ && tar xf openssl*.gz \ && cd openssl* \ && ./config --prefix=/usr/local/openssl && 2024-10-17 运维 #CentOS #Python
kafka集群搭建指北-Broker端参数 1.配置存储信息首先 Broker 是需要配置存储信息的,即 Broker 使用哪些磁盘。那么针对存储信息的重要参数有以下这么几个: log.dirs:这是非常重要的参数,指定了 Broker 需要使用的若干个文件目录路径。要知道这个参数是没有默认值的,这说明什么?这说明它必须由你亲自指定。 log.dir:注意这是 dir,结尾没有 s,说明它只能表示单个路径,它是补充上一个参数用的。 这两 2024-07-16 大数据 #CentOS #Kafka #集群
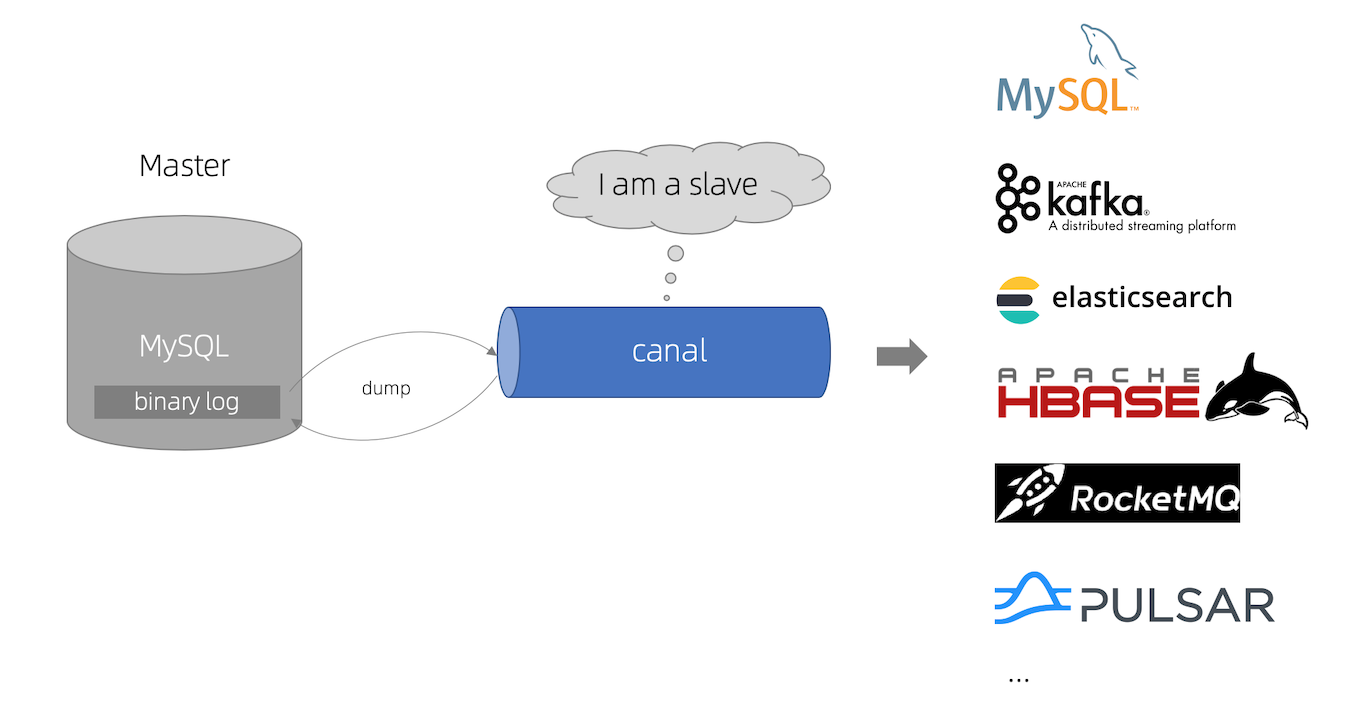
Canal增量解析MySQL(阿里云 RDS)并解决本地binlog被清理后自动下载oss上的binlog 1.问题介绍可参考github issue描述: https://github.com/alibaba/canal/issues/727 如果用户使用binlog解析工具,链接aliyun RDS需要解决几个方面的问题: 账号权限问题 阿里云 RDS早期控制台创建的账号,默认没有binlog dump需要的权限,目前创建的账号默认自带了权限,不需要做任何额外的处理,是否包含必须的权限,也可以直 2024-04-01 数据库 > 大数据 #MySQL #大数据 #阿里云 #Canal
Samba服务配置 1.Samba简介1987年,微软公司和英特尔公司共同制定了SMB(Server Messages Block,服务器消息块)协议,旨在解决局域网内的文件或打印机等资源的共享问题,这也使得在多个主机之间共享文件变得越来越简单。到了1991年,当时还在读大学的Tridgwell为了解决Linux系统与Windows系统之间的文件共享问题,基于SMB协议开发出了SMBServer服务程序。这是一款开源 2023-10-18 运维 #Linux #文件共享 #Samba
Golang语言操作RabbitMQ 1.准备1.1 安装包依赖go get "github.com/streadway/amqp" 1.2 官方文档https://github.com/rabbitmq/rabbitmq-tutorials/tree/master/go 2.普通模式2.1 生产者package main import ( "fmt" "log" "os" "strings" 2023-08-14 开发 #Golang #Go #消息队列 #RabbitMQ